Last week the AIUC-1 Consortium published After Mythos: Defending at Machine Speed. More than two hundred CISOs, GRC leaders, and security researchers, including people from CISA, the Cloud Security Alliance, and Fortune 500 security organizations, put their names to a single argument: the economics of offensive security just changed, and the controls most of us run were calibrated for a world that is ending in months, not years.
The trigger was the reported capabilities of Claude Mythos in offensive cybersecurity, but the paper is careful to say this is not a vendor story. Nobody set out to build an offensive cyber tool: the capability emerged as a byproduct of training a frontier model to be good at writing code, and surfaced only after the fact. That is why the paper treats it as an industry-wide inevitability rather than one vendor's doing. Frontier peers reached parity within weeks, and open-weight models wrapped in purpose-built orchestration are not far behind. The paper cites a working exploit on the first attempt for more than 83% of vulnerabilities, thousands of high-severity findings across every major operating system and browser, and an OpenBSD flaw that had survived twenty-seven years of expert review and decades of fuzzing.1 Breakout times are measured in seconds; one documented intrusion began exfiltrating data four minutes after initial access.2
There's no need to relitigate the threat model here. The authors did that well, and the survey result tells you how the people running these programs feel about it: asked to rate their preparedness for a Mythos-class incident, fifty-two security executives put themselves at an average of 4 out of 10.1
The imperative I want to emphasize is the second of the three, because it's the one we've been in a building frenzy over at NOFire lately: design for breach. Specifically, what "design for breach" has to mean once the thing you're trying to contain is not a stolen credential or a foothold on a VM, but an AI agent you deliberately gave access to production.
The agent is the fastest-growing population of credentialed actors you have
Here is a line from the paper that every engineering leader should sit with:
Practically, a remediation agent will have write access to production, and be a high-value target for adversarial manipulation.
After Mythos: Defending at Machine Speed
The thing we are racing to deploy, the agent that triages the alert and ships the fix at machine speed, is by construction a high-privilege actor whose entire behavior is determined by text it reads at runtime. Logs. Tickets. Stack traces. Tool output. A teammate's Slack message. Any of those is an input, and any input is an injection surface.
The agent does not have to be malicious to do damage. It has to be wrong once, or be talked into being wrong once, while holding write access to your environment. That's a much lower bar than "compromised," and it's a bar that gets cleared accidentally all the time.
Most of the conversation about agent safety tries to solve this inside the model: better system prompts, guardrail models, refusal training, "you must never run destructive commands." That work matters, and I'm glad people are doing it. But none of it is a control I can stand behind in a production review, for two reasons that have nothing to do with how good the model is:
- The model is probabilistic. It produces a plausible action, not a guaranteed-safe one. You can lower the probability of a bad action; you cannot drive it to zero, and you cannot prove the bound holds for inputs you haven't seen.
- The model can be manipulated by its inputs. A guardrail expressed in the prompt lives in the same space the attacker is writing into. Anything the agent can read, an attacker can try to use to renegotiate the rule.
So the conclusion is blunt, and the paper's "assume breach" framing only works if you take it literally: treat every agentic workload as untrusted. Not "trusted but monitored." Untrusted, in the same way you'd treat a binary a stranger emailed you. The agent's good intentions are not a control. Its training is not a control. The only things that count as controls are the ones it cannot talk its way around.
In-band controls bend. Out-of-band controls don't.
The most useful sentence in the whitepaper sits in the "make compromise local" section:
The practical priority is to push as many controls as possible outside the context window (i.e., gateways, IAM, network paths, and execution environments) so that actions are enforced by architectural constraints.
After Mythos: Defending at Machine Speed
This is the whole game. There are two kinds of controls available to you:
-
In-band controls live inside the context window: the system prompt, tool descriptions, the model's own judgment, instructions like "ask before deleting." They are soft because they share a trust domain with the attacker's inputs. The same channel that carries the malicious log line carries your rule about not trusting log lines. The model arbitrates between them, probabilistically, at machine speed, under adversarial pressure. That is not a boundary. That is a suggestion.
-
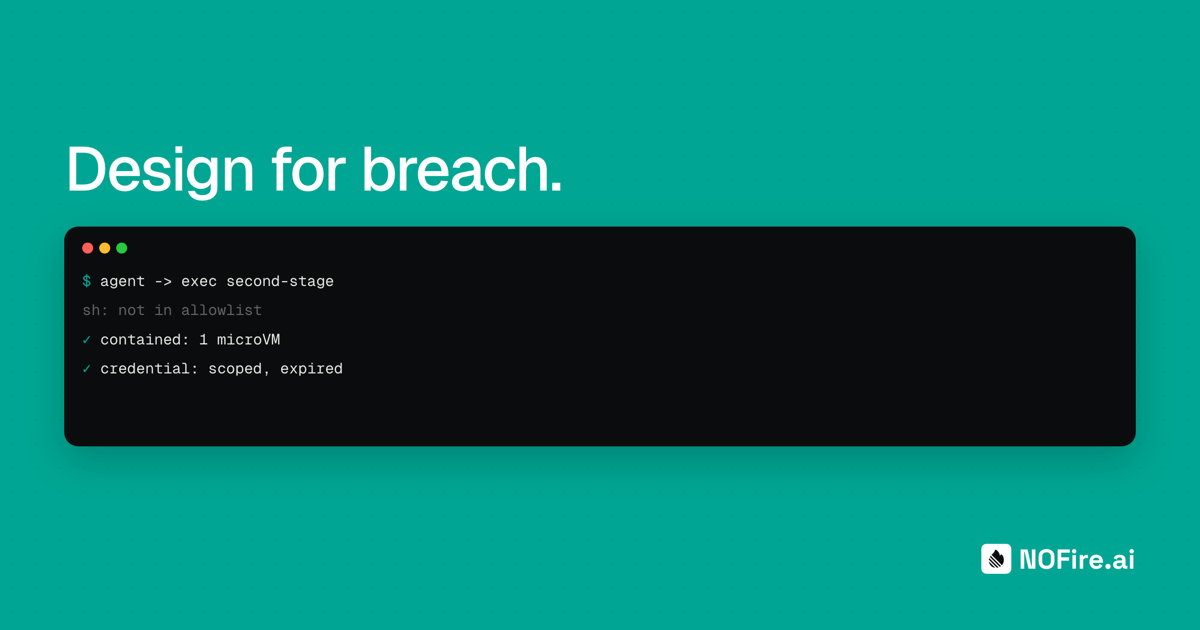
Out-of-band controls live outside the context window: in the network path, the identity system, and the execution environment. The agent cannot read them, cannot reason about them, and cannot renegotiate them, because they are enforced by a layer it does not run in. The paper's own example is binary allowlisting: even if the model finds a vulnerability and writes the exploit at machine speed, "the second-stage payload it wants to run will not execute." The allowlist does not negotiate.
Every durable control here is out-of-band. So the design question stops being "how do we make the agent behave?" and becomes "what is the smallest, hardest boundary we can run the agent inside, and what do we enforce at it?"

The hardest boundary you can put under an agent is the execution environment
Walk the isolation options the way a security review should, and weigh what each one buys you.
A sandbox in your application code. A function-calling allowlist, a tool dispatcher with some validation. This is in-band by another name. The agent's reasoning and your enforcement run in the same process, the same trust domain. One bug in tool dispatch, one path you didn't think to validate, and the boundary is gone. Useful for shaping behavior; worthless as a containment story.
A container. Now you have Linux namespaces, cgroups, and seccomp. Better than running with nothing, but not real isolation: a container still shares the one thing with the host that matters most here, the kernel. The Linux syscall surface is vast, it is under active exploitation, and a single local privilege escalation turns "contained in a container" into "running on the host." Container escape is precisely the second-stage move the paper is warning about. With an adversary that finds and weaponizes kernel bugs at machine speed, "our kernel is patched" is a hypothesis with a shrinking shelf life, not a control. You're betting containment on the largest attack surface in the system.
A microVM. The agent runs against its own minimal kernel, inside a guest, and the boundary between guest and host is the hardware virtualization layer: Intel VT-x or AMD-V, enforced by KVM. To reach the host, the agent no longer has to find one bug in a thirty-million-line shared kernel. It has to break out of a hardware-enforced boundary through a deliberately tiny, heavily scrutinized virtual machine monitor. That is a categorically smaller and harder surface, and it is the difference between "we hope the kernel holds" and "escape requires breaking the CPU's isolation guarantees."
That last option is the one we chose, and it's the foundation everything else at NOFire sits on.

How NOFire runs it: urunc, one microVM per agentic process
Every agentic process in NOFire runs inside its own microVM. We do that with urunc, the CNCF sandbox container runtime purpose-built for single-application kernels and unikernels.
The engineering choice that makes this practical is that urunc is OCI-compatible: it presents as a containerd shim, so the microVM boundary slots into the container and Kubernetes tooling you already run. You schedule an agent task the way you schedule a pod. What actually boots is not a namespace sharing the host kernel; it's a microVM with its own minimal kernel, behind a boundary the CPU enforces rather than one you're trusting the host kernel to hold, started for that task, with an attack surface measured in the handful of devices the guest is given rather than the full breadth of a general-purpose OS.
That OCI compatibility is not a detail; it's the reason this gets adopted instead of admired. Nobody gets to throw away their platform to add isolation. If the hard boundary isn't invisible to the orchestration layer, it doesn't ship. urunc lets the strong boundary hide behind the interface every platform team already speaks.
The properties that matter for "design for breach" fall out of running things this way:
- No shared kernel Not with the host, not between agents. One agent's microVM is not one kernel bug away from another's.
- Minimal guest There is no general-purpose userland to live off. The "land and pivot" playbook assumes a shell, a package manager, an interpreter, a toolchain. A thin guest doesn't hand the attacker those primitives.
- Per-task and ephemeral Boot is cheap enough to stand up a fresh microVM per action and tear it down after. There is no long-lived box accumulating state for the next intrusion to inherit.
The hard controls in and around the boundary
Isolation contains a breach. It does not, by itself, stop an agent from doing harm with the privileges you legitimately handed it. So around every microVM we enforce a set of controls, all of them out-of-band, all of them things the agent cannot reason its way past because it doesn't run in the layer that enforces them.
Scoped, short-lived, non-human identity. Each agent task gets its own managed identity, provisioned for that task, carrying exactly the entitlements the task needs and nothing more, and expiring when the task ends. No ambient cloud credentials sit inside the guest waiting to be harvested. This is the paper's "first-class managed non-human identities, with provisioned IAM, scoped entitlements, clear ownership, and lifecycle controls," enforced at the identity layer rather than promised in a prompt.
Egress allowlisting on the network path. A microVM can reach only the specific endpoints its task requires. Exfiltration to an attacker-controlled host is not prevented by a policy the agent can read and argue with; it's prevented by there being no route. The paper's four-minutes-to-exfiltration figure assumes a path out. Remove the path.
Binary and syscall allowlisting. The second-stage payload does not execute, for the same reason the paper gives: an allowlist doesn't negotiate. Combined with a minimal guest, there is very little to allow in the first place, and the gap between "the model wrote a working exploit" and "the exploit ran in your environment" is exactly where you want the fight to happen.
Mediated, read-only-by-default actions. This is where our Context & Control Model does the work. The agent does not hold production's keys. It holds a request. Every mutating action is evaluated against a live model of your production before it executes, bounded by what your team has defined as safe, and only then carried out within that bounded envelope. "AI reasons, humans decide" is not a tagline here; it's an architectural fact about where the authority to change production actually lives. The agent proposes; the control plane decides and executes.
An immutable audit trail. What triggered the action, what it evaluated, what ran, what it returned. Compliance gets that record for free. The real reason it exists is forensics and trust: when an agent acts in a production-critical path, you need to be able to reconstruct exactly what happened, after the fact, from a log the agent could not edit.
Containment is half of it. Design for recovery too.
The paper makes the point that even well-contained breaches sometimes succeed, and asks for recovery to be designed in rather than bolted on. Running agents as per-task ephemeral microVMs gives you most of that for free. A compromised agent task is one disposable VM and one scoped, already-expiring credential. You kill it and replace it from a known-good image, and because nothing is shared, there is no poisoned state for the next task to inherit.
That is what "make compromise local by design" looks like when you apply it to the fastest-growing population of credentialed actors in the enterprise. The blast radius of a compromised agent is one task's microVM and one task's credential. Not the host. Not the other agents. Not production.

A boundary you haven't attacked is a hypothesis
One more line from the paper, this one from David Campbell at Scale AI, and it belongs on the wall of every platform team shipping agents:
Containment that hasn't been tested under machine-speed adversarial pressure is a hypothesis, not a control.
David Campbell, Head of AI Security Research, Scale AI
So we test it the way the paper says to. We assume the agent is the adversary and we probe the boundary continuously: can a manipulated agent reach a route it shouldn't, escalate beyond its scoped credential, run a second-stage binary, or break out of its guest? When the answer is yes, that's a finding that blocks, not a footnote in a quarterly review. Static assurance ("we validated this six months ago, it's marked compliant") is exactly what the threat curve has made obsolete. The boundary either holds under live adversarial pressure today or you don't actually know whether it holds.
What we are building right now: a policy engine on the hot path
Hardware isolation and the controls around it are the substrate. They contain a breach and bound what a single agent task can touch. The layer we are building on top of that substrate, right now, is a policy engine that makes a decision about every action an agent attempts, while it attempts it. This is where our current build is concentrated, and our design partners get hands on it early: they run it against their own stacks before it ships and help us calibrate the bands, the scoring, and the enforcement defaults.
We hold every control in it to one test, and it's the test I'd recommend to anyone building here: impossible, not tedious. Friction-only controls (rate limits, an extra approval hop, a longer timeout) fail against an agentic attacker, because an agent has infinite patience and will simply pay the friction. The controls that survive are the ones that remove a capability rather than throttle it: deny the syscall, grant no network path, discard the write. Paths that don't exist beat paths that are merely inconvenient.
The engine has two halves. A mechanism that senses and acts: host-side introspection watching what the guest actually does at the syscall, network, and file-access layers; a policy agent sitting on the hot path; and enforcement primitives down at eBPF/LSM, just-in-time network grants, and copy-on-write at the filesystem. And a decision layer, the brain, that scores each action, through deterministic heuristics and an ML risk score, into one of three bands:
- Legit. Allow and commit. The action passes through, or the write is committed to base.
- Dangerous. Deny and discard. The operation is blocked and alerted.
- Borderline. Speculate and gate. Hold the action, and decide on score, escalation, or a TTL before anything reaches production.
The borderline band runs on an execution branch. A borderline-band write does not touch the base filesystem; it lands in a copy-on-write layer sitting next to the policy agent. Policy then either commits the branch (merges it into base) or discards it, dropping the branch so nothing ever touched production. Commit-or-discard for agent writes makes a mutating action reversible by construction: the default for an uncertain change is that it leaves no trace, not that it lands and you clean up afterward.

The same principle runs through identity and access. No standing access for agents; network reach is granted just-in-time, with a full TTL lifecycle (request, evaluate, grant, revoke), and TTLs measured in minutes, not days. Each agent workload is an identity-bound sandbox with an attested hardware root, so a credential lifted from a compromised host cannot be replayed from anywhere else. And enforcement is confidence-phased: deterministic rules enforce first, while ML-scored borderline decisions stay audit-only until they are calibrated, then enforce. Audit before enforce: you climb from alerting to automated containment to orchestrated response on purpose, not by flipping every control to "block" on day one.
If you want the external frame for this, it maps onto Anthropic's Zero Trust for AI Agents,3 which grades controls across three maturity tiers: Foundation, Advanced, and Optimized. Hardware isolation, attestation, just-in-time access, and continuous authorization are what put you in its most hardened tier. For the infrastructure substrate (isolation, identity, enforcement, integrity) that tier is the only one that holds against a machine-speed adversary, so it's what we build for by construction, not a later upgrade.
Where this leaves us
The consensus in After Mythos landed where we already were. Assume breach has stopped being a contingency model; for machine-speed ecosystems it is the operating model. For AI agents in production, taking that literally has a specific meaning. Treat the agentic workload as untrusted. Run it inside the hardest boundary you can put under it, which today is a hardware-isolated microVM, not a container and certainly not a sandbox in your own process. Push every real control out of the context window and into the identity system, the network path, and the execution environment, where the agent cannot renegotiate them. Govern every mutating action against a live model of your production. And keep attacking your own boundary, because a containment story you haven't broken is a story you're telling yourself.
We didn't add security to an agent platform. We built the execution boundary first and let agents act inside it. That ordering is the entire point, and it's why I'm comfortable putting NOFire agents in the path of production changes that I would never hand to an agent running anywhere else.
If you're putting agents anywhere near production, the question was never whether they'll be targeted. It's whether the boundary holds when they are. If you'd like to see ours on your stack, request a demo.
Footnotes
-
AIUC-1 Consortium, After Mythos: Defending at Machine Speed (2026). Statistics and quotations attributed to "the paper" are drawn from this whitepaper. ↩ ↩2
-
CrowdStrike, 2026 Global Threat Report, the source the whitepaper cites for breakout and exfiltration times (fastest observed breakout: 27 seconds). ↩
-
Anthropic, Zero Trust for AI Agents. ↩

