Kubernetes troubleshooting isn’t just about spotting a failing pod; it’s about uncovering why it’s failing in the first place. While identifying a CrashLoopBackOff is easy, getting to the real root cause is often anything but.
Traditional debugging methods force on-call teams to dig through logs, metrics, traces, and multiple dashboards to reconstruct the failure, while ephemeral pods take critical clues with them when they restart. Kubernetes’ own alerting often adds to the noise, making it easy to miss the real problem hidden beneath surface-level failures.
Kubernetes Troubleshooting is Hard
1. Too many alerts
Pods restart all the time; it’s part of Kubernetes’ self-healing nature. But how do you tell the difference between a transient issue and an underlying system-wide failure? With limited context, engineers often chase false positives, only to realize later that a deeper issue (like cache failures or resource starvation) was causing the pod crashes all along.
2. CrashLoopBackOff hides critical clues
A pod that crashes takes its runtime state with it, resetting memory and leaving little trace of what actually went wrong. By the time you investigate, the original condition that triggered the failure may be long gone. Traditional troubleshooting methods require engineers to piece together logs, metrics, and traces manually, often while juggling multiple dashboards.
3. Observability Data Madness
Kubernetes produces tons of telemetry data (logs, metrics, traces) but only a fraction of it is relevant to solving an issue. Engineers waste time opening multiple dashboards, digging through scattered logs, and correlating different data sources. The more complex the architecture, the harder it becomes to pinpoint cause-and-effect relationships that explain what really happened.
Agentic AI Incident Response Team
1. Multi-layered Root Cause Analysis with Agentic AI
NOFire AI doesn’t just react to alerts; it investigates. Our Agentic AI team runs multi-dimensional analysis, inspecting:
- The pod itself (resource limits, events, error logs, deployment events, USE metrics)
- The service running on that pod (RED metrics, dependencies, upstream/downstream impact)
- The broader system impact (cache misses, and infrastructure-wide failures)
Instead of chasing individual symptoms, NOFire AI maps out the entire chain of events leading up to the failure.
2. A Knowledge Graph that connects the dots
Our dynamic knowledge graph links logs, metrics, traces, and service dependencies, allowing NOFire AI to understand how failures cascade across your system. Instead of showing an isolated pod failure, it surfaces:
- How cache failures led to memory exhaustion, which caused the pod to crash.
- Whether other services share the same failure pattern across namespaces.
- Whether the issue is part of a larger system-wide anomaly.
This ensures engineers aren’t just treating symptoms; they’re fixing the root cause.
3. AI-Powered Evidence, Timelines, and Fixes
When NOFire AI identifies an issue, it doesn’t just highlight what went wrong; it explains why, backing it up with:
- A root cause summary based on multi-source telemetry analysis
- A detailed timeline reconstructing the incident
- Supporting evidence from logs, traces, and metrics
- A recommended resolution based on real operational data
With this, engineers no longer need to switch between dashboards. The right insights arrive when they need them most.
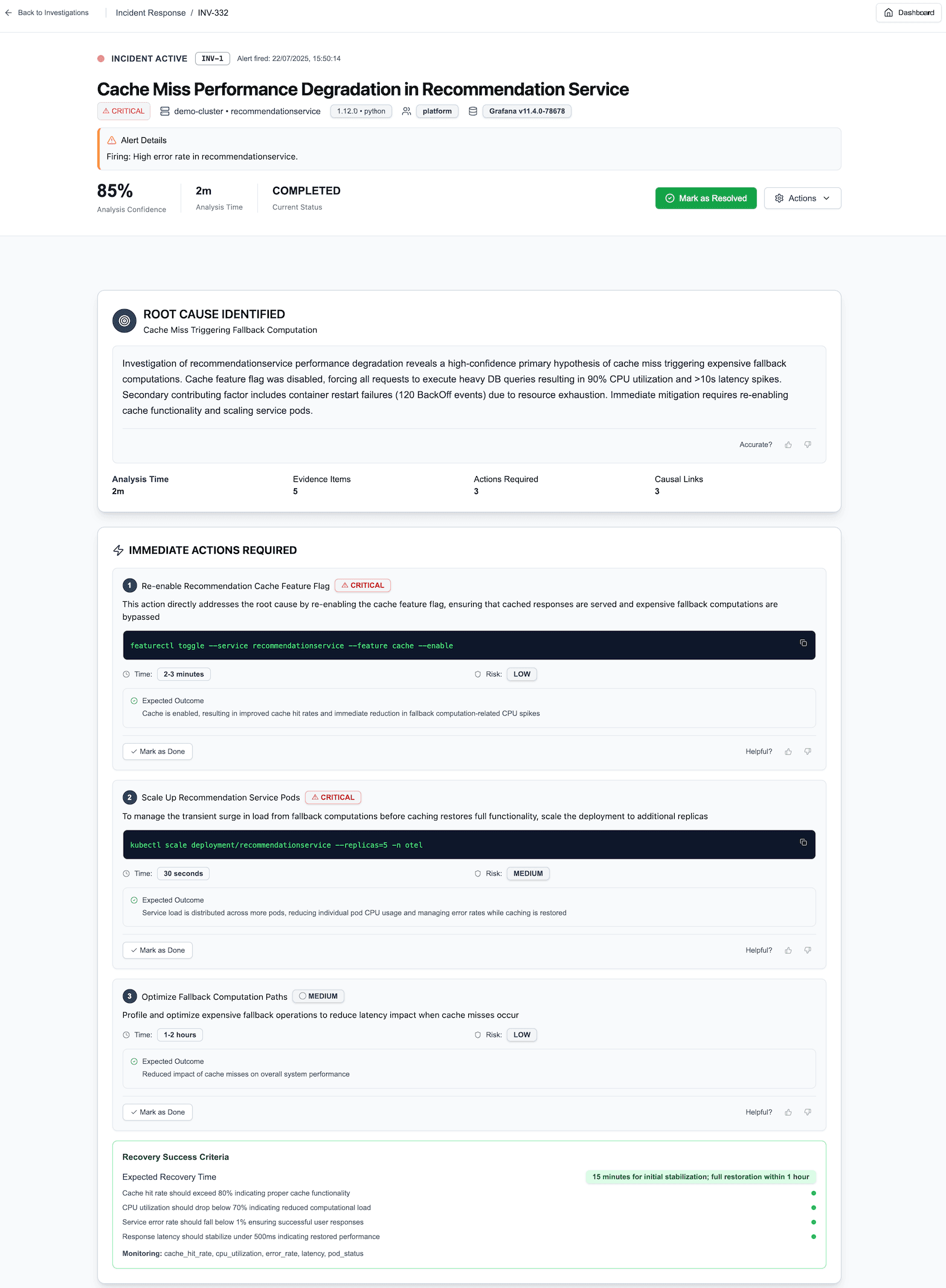
Goodbye data overload, Hello actionable insights
Instead of manually digging through logs and metrics, NOFire AI cuts through the noise and delivers actionable root cause analysis in minutes. By combining Causal AI and Generative AI, it understands cause-and-effect relationships and provides clear, evidence-backed resolutions, not just more data to sift through.
Don’t let CrashLoopBackOff hide critical failures. The next time let NOFire AI agentic incident response team to uncover the true root cause.


